第七单元 音频和语音

|
第七单元 音频和语音 |
|
今天,数字技术统治着音频应用领域。随着卫星通信、IP电话、蜂窝电话、MP3播放器的普及,数字技术正在广播、娱乐、电信、录音等领域取代模拟技术。在这些设备中,数字处理器在将复杂的声音转换为比特流。进行数字音频信号处理的第一步就是编码过程。
数据带宽是设计者考虑选用什么音频编解码器的第一要素。人类听力频率范围在5Hz~ 20 kHz之间,动态范围为120 dB(见表1)。直接进行数字化,所需Nyquist采样率至少为40 kHz,立体声需要两路音频通道。CD音频采用44.1 kHz 采样率和16-bit样本(96 dB动态范围),立体声数据率为1.4 Mbits/sec。此外,还需要信道编码、纠错编码等附加开销。所以,CD音频的总体数据率为4.3 Mbits/sec。(下表略)
对于很多应用场合,这么高的数据率需要进行压缩。压缩分为有损和无损两类。无损压缩利用的是信号中的统计冗余。例如,对英语进行编码需要至少5个比特才能代表26个字母。但是,26个字母的使用率去不相同。例如,在大段文字中,字母E的出现率为13%,而字母Z的出现率则不足1%。使用变长码给于字母E较少的比特,给于字母Z较多的比特,那么在不损失任何信息的前提下比特总量就会减少。
遗憾的是,无损压缩还无法将音频数据率降低到可用范围。其压缩比不会超过2:1。所以,音频编解码器必须采取有损压缩技术。
有选择消除
有损压缩有选择地将信息从信号中消除掉。一个简单的例子就是利用“检测到的静音”。当音频信号中出现了“暂停”,就可以使用某个代码替代所有“静音样本”,解码时再重新插入这些“静音样本”。
有损压缩会导致音质下降。以“静音检测”为例,重建的“静音期”缺乏背景白噪声。在某些应用场合,出现这种状况会让人不舒服。
在过去几十年间,大量各种各样的数字音频编码标准出现了——因为开发者必须考虑许多权衡点。每一种应用领域都存在着数据带宽、音质、处理迟延和其它设计因素间的最佳组合,每一种应用领域也都开发出了自己的音频压缩标准。在这些形形色色的标准中,也存在着某些音频信号处理方法的共同点。音频编解码方法可分为三大类:直接音频编码、感知音频编码和合成编码。
在直接音频编码中,最主要的权衡点在于数据率和音频带宽。在编码前对声音进行滤波,可以降低正确数字化所需的Nyquist采样率。此外,还可以限制信号的动态范围。这两种处理都是电话通信中的标准做法。人类语音的能量集中于200 Hz~3.2 kHz频段之间。此外,大声喊叫的音量也只有70 dB。因此,12比特就足够完成转换了。通过信号滤波和8 kHz采样,电话系统比特率降至96 kbits/sec。对于听者而言,这样的音质就足以通过捕捉语调细微变化来分辨说话人了。对于电话交谈,这样的音质就可以了。不过,对于音乐而言,这样的音质是不行的。调幅广播拥有类似的音频带宽。
利用差异
对于音乐和宽带音频,直接编码必须采取另外一种方法。最常见的是图1所示的“自适应差分脉冲编码调制”(ADPCM)。在该方法中,输入信号先经过一个自适应预测器,然后对输入信号和预测值的差异进行编码。如果预测器工作出色的话,差异会很小,编码所需比特数就会很少。
当然,声音也可能从无到有,少量比特数就会截断这些大信号。预测器的自适应特点通过改变量阶来应对大信号——这样使得比特精度能够更好地匹配信号。这么处理会导致——当信号急速变化时(出现高频信号时),输出出现斜率变化和局部过冲。很容易推算出——ADPCM将获得4:1的压缩效果。ADPCM用在许多音频应用中,如某些类型的波形文件(.wav)和许多国际电话标准。
感知音频编码寻求更高的压缩比,它利用了人耳听觉特征。其目标为——在确保“解码音频信号”与“原始音频信号”零差异或微差异的前提下,去除音频信息。最简单常见的方法称作“压扩”——它利用了人耳对音量变化的响应特点。
人耳对于音频功率的响应呈现对数特点——大约为e1/3(声音功率增强10倍,人耳感知的响度只有2倍提高)。我们只能感觉到约1 dB功率的变化,120 dB音频信号变化范围(从“听不到”到“感觉刺耳”)只包含120个可感知音量量阶。“压扩”利用了这一点,按照信号幅度调整量化间隔。对于小信号,量阶较密集;对于大信号,量阶较疏松。这样一来,涵盖整个信号范围所需的量阶就减少了。典型的电话压扩能够将原本需要12个比特的语音信号量化为8比特进行传输和重建,将数据率降低至64 kbits/sec。
压扩
常用压扩方法有两种。在北美,电话里常用µ率压扩;在欧洲,常用的是A率压扩器。二者的计算方法是近似的。
µ律压扩方法定义如下:
![]()
A律压扩方法定义如下:
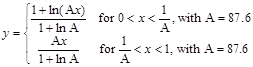
这两个公式采用非线性运算将12-bit输入信号映射为8-bit输出信号,丢弃了人耳听不出来的大音量信号中的信息。
这种编码方法只利用了人耳对于声音信号的幅度响应特点。对于频率,人耳的响应特点也是对数型的——在50 Hz ~100 Hz频率范围感受到信息和在10 kHz ~ 20 kHz一样多。此外,幅度和频率还交互作用于人耳,弱信号会被邻频强信号掩蔽掉。复杂的感知编码方法利用了上述特点、降低了数据率、构成了AAC(MPEG-2高级音频编码器)和Dolby AC3等音频编解码器的基础。
图2展示了感知编码音频编解码器的总体框架。输入信号进入滤波器组,各频段信号独立编码。将各频段信号能量和感知模型进行对比,确定每个频段所需的量阶大小。如果某个频段的强信号将会掩蔽临近频段的弱信号,量化器就不会对被掩蔽信号进行采样。在量化之后,无损编码进一步降低比特数量,为信道编码和数据打包做准备。
感知编码可以明显地降低比特率(见表2)。以1.4 Mbit/sec的CD立体声为例。感知编码可将其数据率降至128 kbits/sec而不会造成可感知的音质下降。
对模型(而非波形)进行编码
感知编码要费很大劲儿才能将音乐等宽带音频的数据率降下来,它也无法满足无线通信应用对于压缩水平的需求。在这些应用场合,数据带宽很重要,音频编解码器无法改变声音样本的外观。编解码器利用了人类语音生成模型——称作“线性预测编码”(LPC)——作为压缩算法的基础。
在大约2~40毫秒的短时间内,人类语音可采用三个参数进行建模(如图2所示)。第一个参数是选择声音源——是随机噪声、还是脉冲序列。随机噪声对应于辅音中的摩擦音——例如,[s]、[f]和[v]。脉冲序列对应于语音中的元音。因为元音音调会发生变化,模型中将脉冲序列频率作为第二个参数。第三个参数是回归线性滤波器系数——该滤波器模拟口腔、喉咙、鼻腔构成的声音通道的响应。
尽管如此形成的声音听上去生硬,但该模型可以用来进行语音合成。它也是“码激励线性预测编码”(CELP)语音编解码器的核心。在CELP算法中,编解码器存储着LPC模型的码本,将模型合成的声音与输入声音片断进行对比,调整对比过程以忽略人耳无法觉察的差异。编解码器在多个模型中选择最佳匹配,然后将码本和错误项传递给接收器。编解码器将反复调整其码本,也需要偶尔传递滤波器系数。
CELP编码的语音质量稍低于其他压缩方法,但仍可为正常交谈提供足够的语音保真度,因为其中的错误项纠正了LPC模型带来的大部分“生硬”。CELP的优势大大超过其带来的音质损失。CELP编解码器可将语音信号数据率压缩至4.8 kbits/sec。
CELP面向语音编码,而不是面向宽带音频;不过,相似的方法也在MPEG-4结构化音频中提出来,用于宽带音频信号压缩。结构化音频方法也传递模型参数,这一点是和CELP相同的;不过,和CELP不同的是,其声音合成模型不是预先确定的。结构化音频编解码器同时传递模型、参数,让它们去容纳一个很宽范围的声音源。
结构化音频、CELP和其他音频压缩算法仅仅是音频信号处理的基础。还有许多系统因素影响着编码算法的选择,如编解码器对信号处理过程带来的延迟。例如,在电话交谈中,说和听之间出现的半秒延迟就可能打断谈话。此外,在出现噪声或出现噪声导致的数据流损坏时编解码器的性能也是需要考虑的系统因素。不过,对设计人员而言,了解这些基础知识就是走向数字音频领域的起点。

| 电子工业出版社 |